|
IT之家 12 月 19 日音讯,苹果公司昨日(12 月 18 日)发布博文,告示和英伟达(Nvidia)相助,通过开源 Recurrent Drafter(ReDrafter)推测解码步调,显赫普及了 AI 大言语模子(LLM)的推理速率。 苹果公司示意 ReDrafter 已集成到 NVIDIA TensorRT-LLM 推理加快框架中,在 NVIDIA GPU 上,每秒生成 tokens 速率最高普及 2.7 倍,有用裁减了用户延长和估量资本。 苹果的机器学习照管东说念主员指出,LLM 越来越多地用于初始坐蓐运用设施,提高推理后果对裁减估量资本和用户延长至关周折。 IT之家征引苹果官方博文,ReDrafter 使用 RNN 草稿模子,连续波束搜索(beam search)与动态树留意力(dynamic tree attention),不错让路源模子每步生成最多 3.5 个 tokens,特出了先前推测性解码手艺的性能。 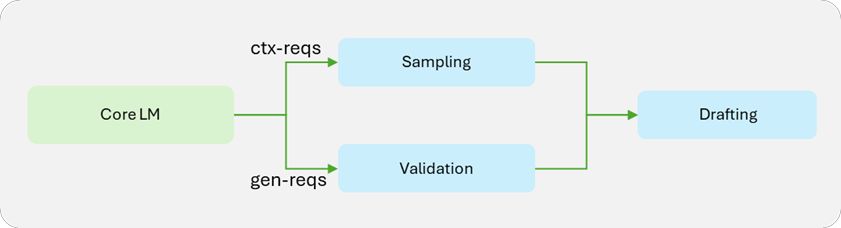 为将 ReDrafter 运用于坐蓐环境,苹果与 NVIDIA 张开相助,将其集成到 NVIDIA TensorRT-LLM 框架中。 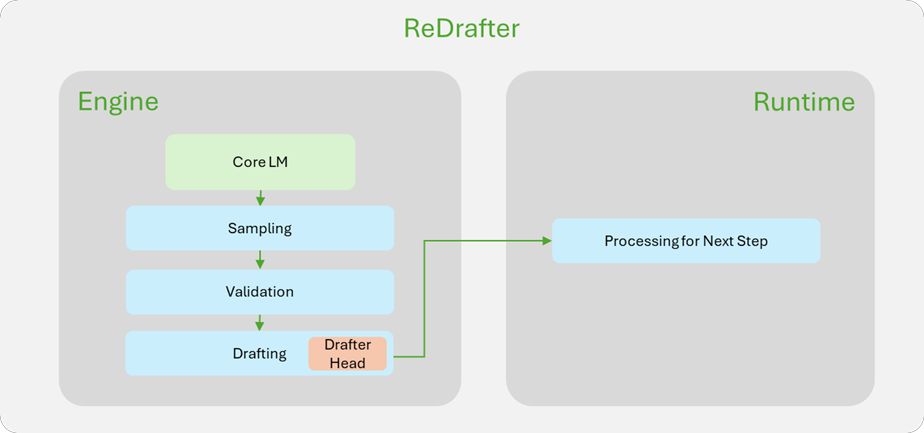 英伟达为此添加了新的运算符并公开了现存运算符,增强了 TensorRT-LLM 对复杂模子息争码步调的适合性。 基准测试终了败露,在 NVIDIA GPU 上使用集成了 ReDrafter 的 TensorRT-LLM 框架,数百亿参数畛域的坐蓐模子的解码速率普及了 2.7 倍。这不仅裁减了用户体验延长,还减少了 GPU 使用数目和功耗。 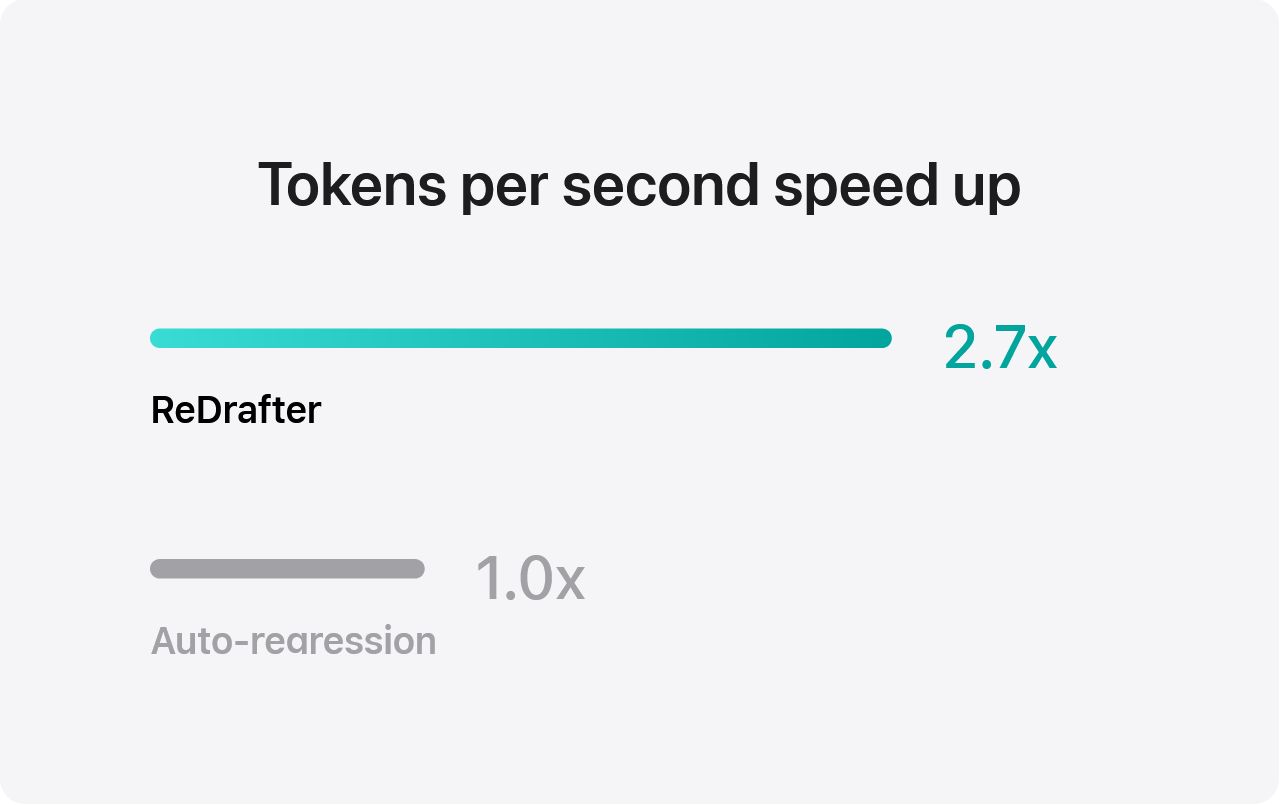  IT之家附上参考地址 Apple collaborates with NVIDIA to research faster LLM performance NVIDIA TensorRT-LLM Now Supports Recurrent Drafting for Optimizing LLM Inference ml-recurrent-drafter Accelerating LLM Inference on NVIDIA GPUs with ReDrafter云开体育 ]article_adlist-->告白声明:文内含有的对外跳转教导(包括不限于超教导、二维码、口令等神气),用于传递更多信息,从简甄选时代,终了仅供参考,IT之家通盘著作均包含本声明。]article_adlist--> 声明:新浪网独家稿件,未经授权拦阻转载。 --> |